搜索和推荐领域比较核心的研究方向是 query 和 doc 或者是 user 和 item 之间的相关度(Relevance)。传统的相关度计算会对 q&d 或 u&i 的组合进行特征提取然后利用 LTR 模型进行相关性得分计算并排序。近年来不断发展的深度学习技术给相关度计算,特别是语义相关度计算引入新的思路和方法。
概述
深度相关模型(Deep Relevance Model)主要分为两个方向:
-
表示模型(Representation-based)
表示模型是基于全局信息的相关度模型。首先分别学习出 query 和 doc 的语义向量表示,然后通过余弦距离等计算向量之间的距离。这个方向的重点在于优化向量表达。代表模型有 A Deep Relevance Matching Model for Ad-hoc Retrieval 等
-
交互模型(Interaction-based)
交互模型是注重局部交互信息的相关度模型。首先得到 query 和 doc 的字词粒度基础表示,也就是词向量的数组;然后进行卷积等交互操作,提取一些字词粒度的匹配信号。代表模型有 DeepRank: A New Deep Architecture for Relevance Ranking in Information Retrieval 等
EMNLP2018 的一篇论文在 PACRR(Position-Aware Neural IR Model for Relevance Matching) 的基础上优化了交互后的 MLP 层结构,取得了更好的效果。我们将争取从 PACRR 的代码出发,洞悉 Deep Relevance 的一个子研究方向,最终得以一窥整体的研究方向。
数据处理
以bioasq数据集为例
-
train/dev/test数据为一个单元素dict,key为queries,value为一个List;每个list元素为一个query,其中包括query_id,query_text,relevant_docs(与该query相关的doc,相关的标准为bm25召回时得分大于2)。retrieved_docs为一个list,包含每个召回的doc,每个doc内部包含doc_id,rank_pos,bm25_score,norm_bm25_score,is_relevant标志位这些字段。

- 词表数为Vocabulary size: 2665547。term2ind为一个字典,key为字词,value为从1递增的index。
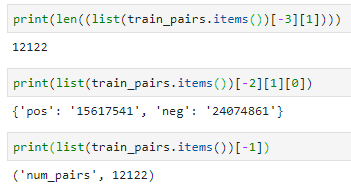
- 将train_data构造成train_pair,同样为dict,keys如下

- queries为双层list,每个子list是query每个词的idx list,共有12122个query

- queries_idf为双层list,每个子list是query每个词的idf list

- pos_docs为双层list,每个子list是每个正样本doc的每个词的idx list

- neg_docs同理
- pos_docs_BM25为单层list,每个数值对应每个正样本doc的BM25值(即query与doc的召回特征)
- 训练集总共产生12122对正负query
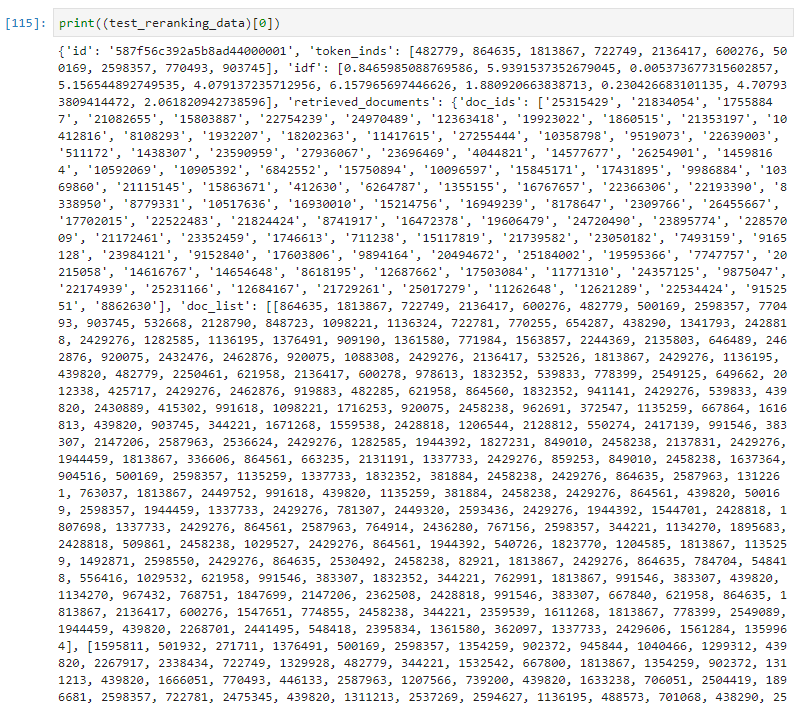
- 构造dev/test_reranking_data,目标是将原有的query通过BM25召回的doc list进行重排,其中dev用于训练阶段,test用于预测阶段。格式如下
模型初始化
| 参数名称 | 默认值 | 说明 | 参数名称 | 默认值 | 说明 | 参数名称 | 默认值 | 说明 |
|---|---|---|---|---|---|---|---|---|
| bi_rnn_out_dropout | 0.3 | dropout比例 | embed | 空,需导入 | 词嵌入向量 | padding mode | post | 在query后padding |
| binmat | Fales | epochs | 100 | 迭代轮次 | predict_batch_size | 128 | ||
| bm25_norm | zscore | 归一化方法 | hidden_size | 50 | qproximity | 0 | ||
| cascade | 100 | kmaxpool | 2 | maxpool窗口大小 | shuffle | false | ||
| combine | 70 | 全连接层神经元个数 | maxqlen | 30 | query最长词数 | simdim | 300 | 相似矩阵维度 |
| context | False | 是否使用上下文信息 | nfilter | 16 | 卷积核个数 | td | false | 全连接不使用time-distributed层 |
| distill | firstk | 蒸馏方法 | numneg | 1 | 每个query的负样本数量 | ud | 0 | |
| use_overlap_features | true | 重叠特征 | use_bm25 | true | winlen | 3 | 卷积核尺寸(ngram) | |
| word_emd_dim | 200 | 词嵌入维度 | use_termbm25 | false | xfilters | 空 |
-
训练总入口:pacrr/utils/pacrr_utils.py文件的pacrr_train函数,传入的主要参数有train_pairs,dev_pairs,dev_reranking_data,term2ind(词表lookup),config(大配置),model_params(模型配置)等。
-
该函数带有Evaluate的内部类,作为训练一个epoch结束后的callback调用。
-
首先将传入的model_params加上训练所需的其他参数,如nsamples/vocab_size/emb_dim,最重要的是将文件中的word_embedding导入到embed字段中,然后使用全部配置参数和embedding进行PACRR的模型初始化。
-
PACRR模型建模等函数在pacrr_model.py中,以model_params先初始化一个MODEL_BASE的类,然后PACRR以MODEL_BASE为基础进行ngram filter的初始化,实际就是cnn的卷积核大小。

-
初始化结束后执行build函数创建模型,query_idf,query_indx(query每个词对应词表位置)为Input层;词嵌入为Embedding层。
- build_doc_scorer函数创建模型内部的打分层doc_scorer,可分别用于pos_doc和neg_docs给出得分
- 根据win_len从小到大创建卷积核;
- 使用cov_dsim_layers函数,根据simdim,maxqlen,filter_size,nfilter,kmaxpool,maxpool_pose,distill创建卷积相似度层,其中包括卷积层,max-pooling层(Lambda),reshape层
- 返回一个scorer,该scorer根据入参doc_input(可为pos或neg)进行模型运算给出得分。
-
pos和neg doc由create_inputs函数进行创建输入层,其中doc_inds为300维大小(simdim)。
-
得分pos_score和neg_scores,再concat成一个list,最后softmax给出pos的概率值,这是training model。
- scoring model只输入query和一个doc,还有idf,然后输出一个打分。
模型结构
PACRR
-
论文模型总体结构
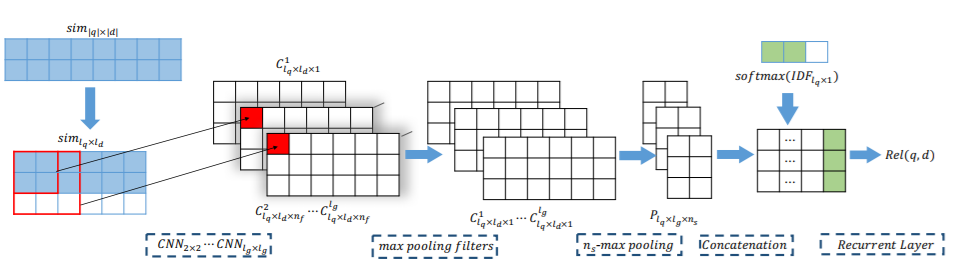
- 代码模型总体结构
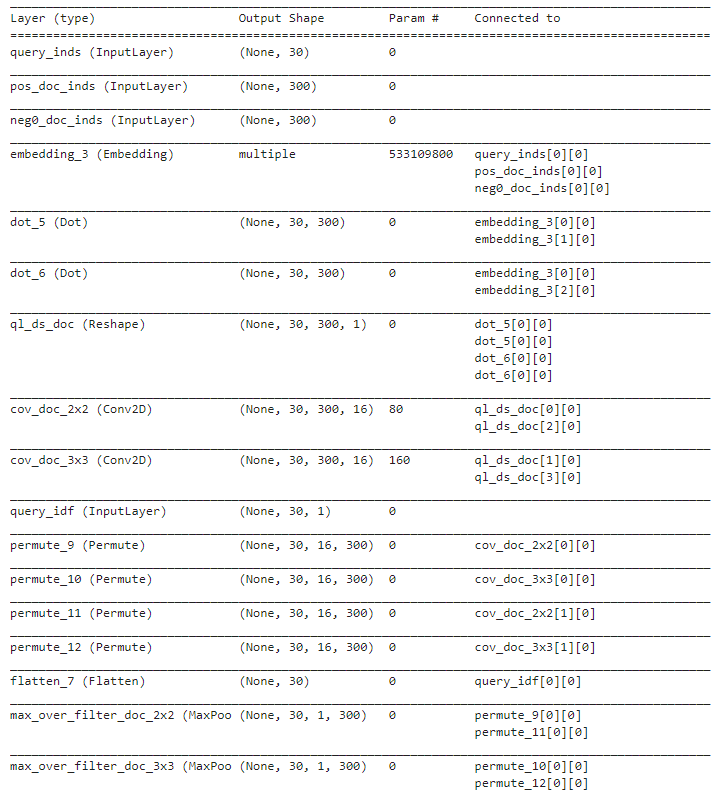
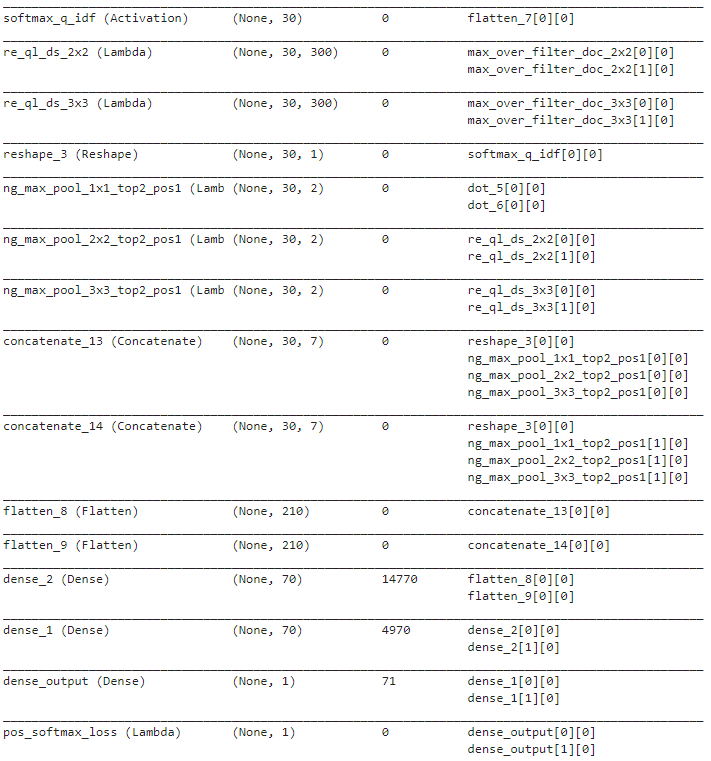
-
输入为query_idx(30dim),pos_doc_idx和neg_doc_idx(300dim);embedding为词嵌入,通过idx取出来后每个词向量。
-
对于query和pos_doc的交互,[30,200]点积[200,300]后得到[30,300]的相似度矩阵;query和neg_doc同理。
-
ql_ds_doc这一Reshape层将以上交互矩阵reshape至维度为3的张量;batch为4,分别是pos和neg用于[2,2]和[3,3]卷积核。
-
cov_doc_2x2和cov_doc_3x3后分别得到两个[30,300,16]张量,卷积核个数为16;idf作为输入层,维度为30。
-
卷积得到4个张量,然后对16个卷积核的结果进行max_pooling,得到[30,1,300]的张量。
-
使用ngram_size=2对doc维度进行max_pooling,提取query的第n个词对应doc最重要的ns个词。3种win_len得到3个[30,2]的张量。
-
对query的idf列表进行softmax得到[30,1],和上面3个张量concat到一起,得到[30,7]的张量;由于分别有pos和neg,共有2个[30,7]张量。
-
flatten成2个[210]的张量,用两层Dense全连接层进行连接,210 -> 70 -> 70 -> 1得到输出。
-
-
训练参数
- embed为词表的embedding,共有2665549个词,每个词的维度为200。
PACRR-DRMM
-
模型总体结构
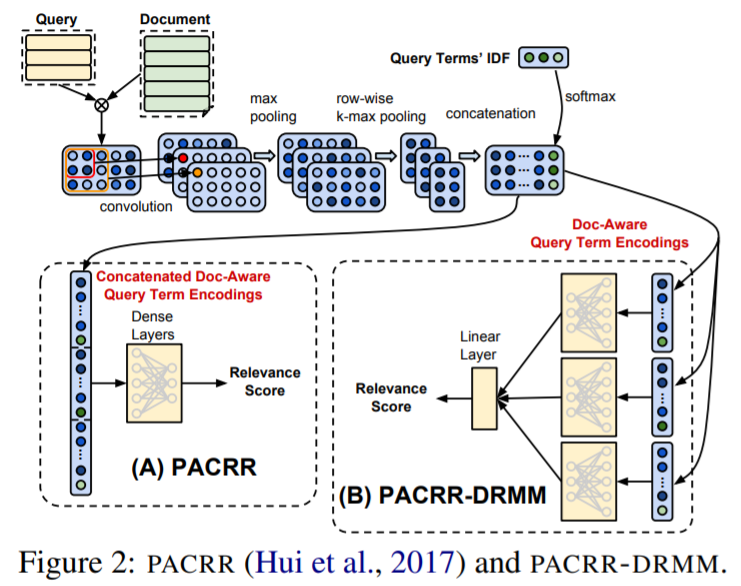
- 与 PACRR 的结构差异
- PACRR
经过 query&doc 交互后,将各个 query term 的向量展平连接为 1 维向量,加入辅助文本信息后(IDF)经过全连接层得到相关性得分。 - PACRR-DRMM
经过 query&doc 交互后,将各个 query term 的向量分别经过全连接层得到各自的相关性得分,然后通过一个线性层融合输出最终的相关性得分。
- PACRR
-
与 PACRR 的参数差异
combine=7,td=true -
与 PACRR 的代码差异

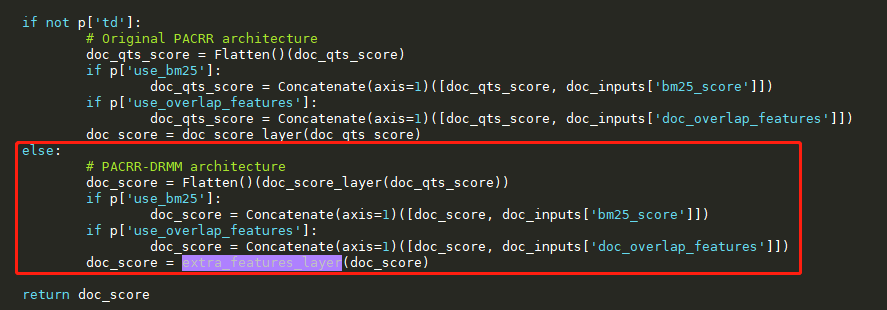 可以看到如果使用PACRR-DRMM,交互后是一个 TimeDistributed 层再接一个 Dense 全连接层。
可以看到如果使用PACRR-DRMM,交互后是一个 TimeDistributed 层再接一个 Dense 全连接层。 - 优化思路
- 作者在文章中提到 PACRR-DRMM 的表现要优于 PACRR,并认为原因可能是 PACRR-DRMM 的 MLP 层的参数是跨 query-term 共享的,而且输入的向量维度更小,最终导致相同层数(两层)的情况下参数更少,使其不容易过拟合。
- 从实际的代码可以看出,PACRR 的 MLP 层的参数个数约为 14770+4970 = 19740 个,而 PACRR-DRMM 应该约为 7*7*30 + 7*7*30 = 2940 个。
个人思考
- 实验尝试过用 PACRR 模型对现有的 LTR 模型进行替换,主要的不同是使用 query&doc 交互的文本特征替代原文的 q-term-idf。效果提升不太明显:多业务的 top1 准确率有升有降,且幅度不大(1个点内);top3 准确率升多于降,平均有 1 个点的提高。
- PACRR 的目标 label 是 one-hot 的形式,相当于 LTR 的 point-wise 训练方式,加入 pair-wise 信息甚至 list-wise 信息可能会提高 LTR 的指标(NDCG等)。
- 如果目标是跨业务跨领域通用的 Deep Relevance Model,那么细粒度的字词向量就非常值得优化,使用 bert 等预训练模型对字词向量进行优化应该是一个可行方向。
- To be continued ..