最近在公司进行C++代码优化,主要是针对大数据量的场景下,算法库的耗时和并发问题。期间发现了一些利剑级别的工具,还有一些值得记录的优化要点,这里一并记录下来。
耗时分析
程序的耗时一般有两个方面,一是 On-CPU 时间:CPU 实际上在进行高密集性计算的耗时;二是 Off-CPU 时间:CPU 此时并没有进行计算,而是其他设备在进行 IO 的等待,例如文件读写,网络传输等。
Perf 工具
Perf 是内置于Linux 内核源码树中的性能剖析(profiling)工具。它基于事件采样原理,以性能事件为基础,支持针对处理器相关性能指标与操作系统相关性能指标的性能剖析。可用于性能瓶颈的查找与热点代码的定位。linux2.6及后续版本都自带该工具,几乎能够处理所有与性能相关的事件。
Perf 基本操作
由于 Perf 是系统自带的一个工具,所以就不需要另外地安装了。直接执行以下指令就可以记录某个 binary 文件执行过程的 cpu 时间分析。
-
记录性能时间
perf record -g your_app.exe
执行完后会在当前目录下生产一个perf.data的文件,其中包含了your_app.exe运行过程的 cpu 性能时间。
-
展示报告
perf report
执行完后会显示一个类似函数调用栈的结构,如下图所示。其中第一列为 cpu 时间占比,cpu 时间占比可能会超过 100%,这是因为调用链的时间归算为一个主函数的 cpu 时间了。如果需要单独显示各个函数的 cpu 时间,可以加上 –no-children 等选项。
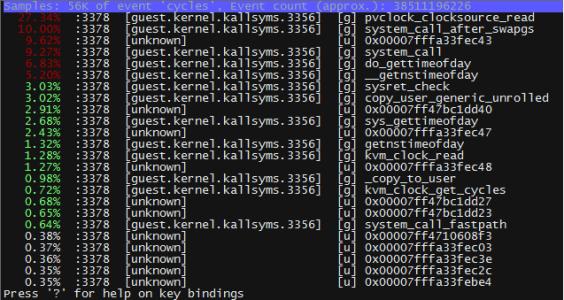
-
分析性能痛点
cpu 时间高且无子函数的函数是优化的重点。定位到函数级别后,再细细剖析逻辑,循环迭代,最终达到期待的性能表现。
FlameGraph
FlameGraph 也就是火焰图,是可以将 Perf 生成的数据以更加形象的方式进行展示的工具。
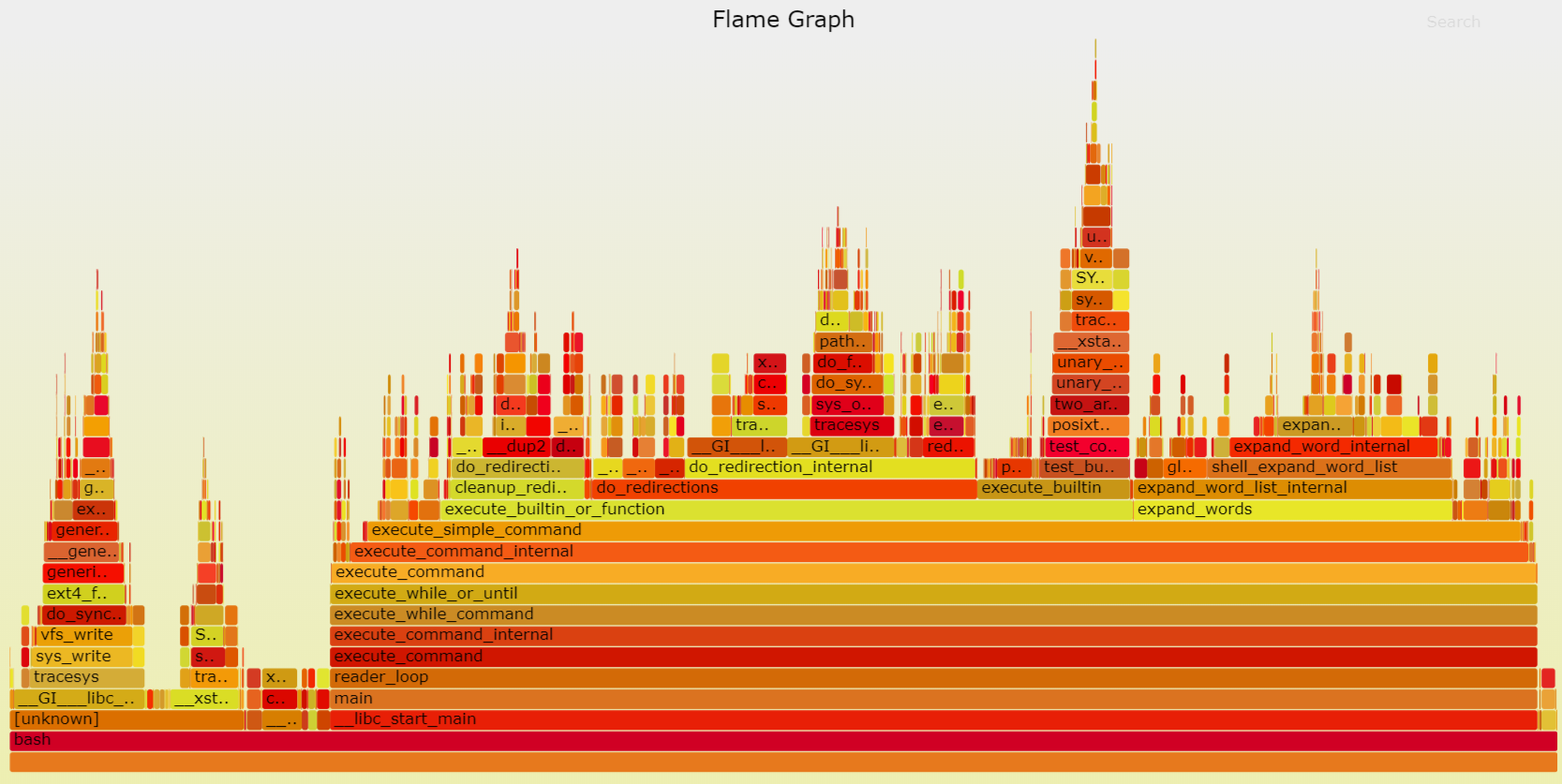
如图所示,火焰图其实是对调用链的可视化。从下至上为一条完整的调用链,横向长度为当前函数及其子函数的 cpu 占用时间。
-
记录 On-CPU 性能
1. git clone --depth 1 https://github.com/brendangregg/FlameGraph.git 2. perf record -g ./concurrent_test_tool -thread_num=1 3. perf script -i perf.data &> perf.out 4. ./FlameGraph/stackcollapse-perf.pl perf.out > out.folded 5. ./FlameGraph/flamegraph.pl out.folded > on-cpu_time.svg -
记录 Off-CPU 性能(block IO time)
1. 开启kernel-debuglevel 2. perf record -e block:block_rq_insert -a -g -- ./concurrent_test_tool -thread_num=1 3. perf script --header | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl --color=io --title="Block I/O Flame Graph" --countname="I/O" > off-cpu_time.svg
定位 block IO time 需要更新服务器对应内核版本的debug信息,具体参考Off-CPU Flame Graphs
C++性能优化要点
-
map 和 unordered_map
众所周知,c++ 中的标准 map 的实现方式为红黑树,其插入和搜索的复杂度都是$o(nlog(n))$;在大数据量场景下,这一复杂度可能也会体现出较为明显的延时。同时,若不要求插入是有序的话,完全可以使用 unordered_map (hash实现)来代替 map。 -
Json库优化
对于配置文件等小数据量的场景,json库可以根据 api 易用性和稳健性等为标准选取。若涉及大数据量的 json 文件读写,必须换用吞吐量大的 Json 库,诸如 RapidJson,Gason等。注意这些库的原位解析选项,如果性能优化瓶颈确实在 Json 读写,可以采用原位解析的方式读取,避免内存复制从而提高性能。 -
复杂循环内避免内存创建销毁
为了保持变量作用域的干净,很多代码会在循环内进行临时变量的创建。如果这些临时变量的创建销毁是个 CPU 高耗行为,那么应当将这个动作放在循环前面进行,整个循环过程只对一个变量进行读写。当然,为了尽量符合“只在变量使用时才创建它”这个原则,应该在循环开始前最近的地方进行临时变量的创建。 -
使用引用传递而非值传递
这个是老生常谈的话题了。使用值传递在函数之间传递参数时,伴随着大量的创建销毁开销。使用引用传递,保证了参数传递的高效性;由于各个函数操作的是同一个对象实例,可以减少出错的机会和降低定位问题的难度。 -
多线程 CPU 使用率较低
此时线程应当是花费了大量的时间在 IO 操作上,一般为文件写入(例如日志写入等)。因为写入文件的 IO 一般都带有锁防止资源冲突,一个典型的例子就是单例模式的 glog。To be continued…